
Not: Bu makale Dmitry Maslov tarafından yazılmıştır ve ilk olarak Hackster.io‘da yayınlanmıştır.
Bu makalede, Mozilla’nın DeepSpeech ASR (otomatik konuşma tanıma) motorunu Raspberry Pi 4 (1 GB), Nvidia Jetson Nano, Windows PC ve Linux PC gibi farklı platformlarda çalıştıracak ve benchmark yapacağız.
2019, geçen yıl, Edge AI’nın ana akıma girdiği yıl oldu. Birçok şirket, kenarda hızlı çıkarım için kartlar ve çipler piyasaya sürdü ve birçok optimizasyon çerçevesi ve modeli ortaya çıktı. Şu ana kadar, makalelerimde ve videolarımda, genellikle bilgisayarla görme için makine öğrenimi kullanımına odaklandım, ancak her zaman gömülü bir cihazda derin öğrenmeye dayalı ASR projelerini çalıştırmaya ilgi duydum. Sorun, yakın zamana kadar bu görev için basit, hızlı ve doğru motorların eksikliğiydi. Bu konuyu yaklaşık bir yıl önce araştırırken, ASR’yi (sadece sıcak kelime tespiti değil, büyük kelime dağarcığı transkripsiyonu) çalıştırmak zorunda olduğunuzda, örneğin Raspberry Pi 3 üzerinde birkaç seçenek vardı:
- CMUSphinx
- Kaldi
- Jasper
Bağlantılar:
Python 3 Yapay Zeka: Çevrimdışı STT ve TTS
Raspberry Pi için En İyi Ses Tanıma Yazılımı
Ve birkaç tane daha. Hiçbiri kurulumu kolay değildi ve kaynak kısıtlı bir ortamda çalıştırmak için özellikle uygun değildi. Bu yüzden, birkaç hafta önce bu alana tekrar bakmaya başladım ve biraz araştırmadan sonra Mozilla’nın DeepSpeech motoruyla karşılaştım. Bir süredir mevcut, ancak yalnızca yakın zamanda (Aralık 2019) ASR motorlarının 0.6.0 sürümünü yayınladılar ve bu sürüm, diğer önemli iyileştirmelerin yanı sıra .tflite modeli ile birlikte geliyor. İngilizce modelin boyutunu 188 MB’dan 47 MB’a düşürdüler. “DeepSpeech v0.6, TensorFlow Lite ile Raspberry Pi 4’ün tek çekirdeğinde gerçek zamanın daha hızlı çalışıyor.”, dedi Mozilla’dan Reuben Morais, haber duyurusunda. Bu iddiayı kendim doğrulamaya karar verdim, farklı donanımlarda bazı benchmarklar yapacağım ve sıcak kelime tespiti ile kendi ses transkripsiyon uygulamamı oluşturacağım. Sonuçların ne olduğunu görelim.
İpucu: Hayal kırıklığına uğramadım.

Aslında bu Firefox kadar mutlu oldum!
Kurulum
Raspberry Pi 4/3B
Arm7 mimarisi için önceden derlenmiş tekerlek paketi varsayılan olarak .tflite modelini kullanacak şekilde ayarlanmıştır ve kurulumu sadece
pip3 install deepspeechBu kadar! Paket kendi içinde tamamdır, TensorFlow kurulumu gerekmez. Tek dış bağımlılık Numpy’dır. Modeli ayrı olarak indirmeniz gerekecek, bunu bir sonraki bölümde ele alacağız.
Nvidia Jetson Nano
Bu makalenin yazıldığı gün itibarıyla (1/22/2020) arm64 mimarisi için önceden derlenmiş tekerlek varsayılan olarak büyük .pbmm modelini kullanıyor. Yani, Github’daki DeepSpeech sürümlerinden indirirseniz, hoş olmayan bir sürprizle karşılaşacaksınız. Swap dosyası 4 GB’a genişletildiğinde, Jetson Nano tam modeli çalıştırabilir, ancak 1.9 saniyelik bir dosya için yaklaşık 18 saniye sürüyor… .tflite model desteği etkinleştirilmiş bir önizleme tekerleği, https://community-tc.services.mozilla.com/api/queue/v1/task/KZMAnYo2Qy2-icrTp5Ldqw/runs/0/artifacts/public/deepspeech-0.6.1-cp37-cp37m-linux_aarch64.whl adresinden indirilebilir.
Bunu indirip şu şekilde kurabilirsiniz:
python3.7 -m pip install --user deepspeech-0.6.1-cp37-cp37m-linux_aarch64.whlPython 3.7’nin kurulu olması gerekiyor! Nvidia Jetson varsayılan olarak Python 3.6 ile gelir.
Windows 10/Linux
Windows ve Linux için .tflite etkinleştirilmiş pip paketinin sürümünü indirmeniz gerekecek.
pip3 install deepspeech-tfliteEğer Python 3.8 kullanıyorsanız, Windows’ta DLL yükleme hatası ile karşılaşabilirsiniz. Bu, DeepSpeech paket kodunda küçük bir değişiklikle oldukça basit bir şekilde düzeltilebilir, ancak ben sadece sorunsuz çalışan Python 3.7 sürümünü kurmanızı öneririm.
Eğer NVIDIA GPU’nuz ve CUDA 10 yüklüyse, GPU etkinleştirilmiş Deepspeech sürümünü tercih edebilirsiniz.
pip3 install deepspeech-gpuBenchmarking
Modelleri, dil modeli ikili dosyasını ve bazı ses örneklerini indirelim.
curl -LO https://github.com/mozilla/DeepSpeech/releases/download/v0.6.1/deepspeech-0.6.1-models.tar.gztar xvf deepspeech-0.6.1-models.tar.gzÖrnek ses dosyalarını indirin:
curl -LO https://github.com/mozilla/DeepSpeech/releases/download/v0.6.1/audio-0.6.1.tar.gztar xvf audio-0.6.1.tar.gzRaspberry Pi 4 çalıştırma:
deepspeech --model deepspeech-0.6.1-models/output_graph.tflite --lm deepspeech-0.6.1-models/lm.binary --trie deepspeech-0.6.1-models/trie --audio audio/2830-3980-0043.wavBaşarılı olursa, aşağıdaki çıktıyı görmelisiniz:
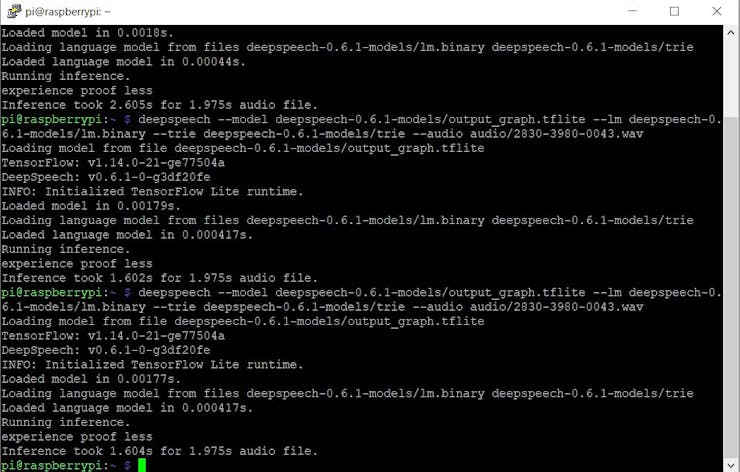
Fena değil! 1.98 saniyelik ses dosyası için 1.6 saniye. Gerçek zamanın daha hızlı.
Nvidia Jetson Nano çalıştırma:
deepspeech --model deepspeech-0.6.1-models/output_graph.tflite --lm deepspeech-0.6.1-models/lm.binary --trie deepspeech-0.6.1-models/trie --audio audio/2830-3980-0043.wav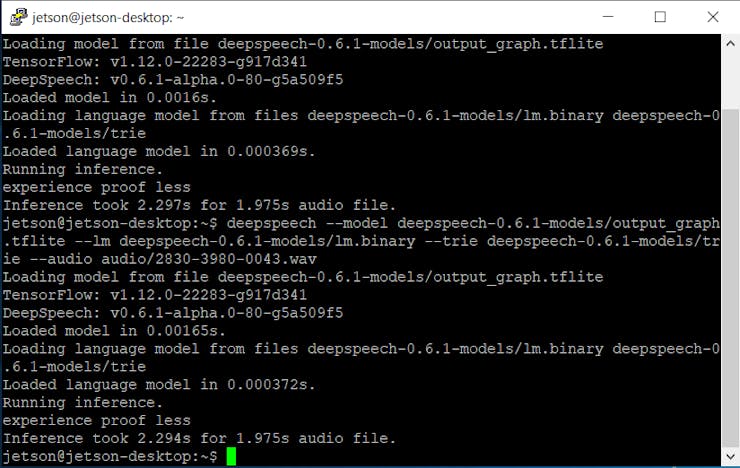
Hm.. Raspberry Pi’dan biraz daha yavaş. Bu bekleniyordu çünkü Nvidia Jetson CPU’su Raspberry Pi 4’ten daha az güçlü. Şu anda arm64 mimarisi için GPU desteği ile önceden derlenmiş ikili dosyalar yok, bu yüzden Nvidia Jetson Nano’nun GPU’sunu çıkarım hızlandırması için kullanamıyoruz. Bu görevin DeepSpeech ekibinin yol haritasında olduğunu düşünmüyorum, bu yüzden yakın gelecekte burada biraz araştırma yapacağım ve o ikili dosyayı derlemeye çalışacağım, GPU kullanarak hangi hız kazançlarının elde edilebileceğini görmek için. Ancak saniyeler hala oldukça makul bir hız ve projenize bağlı olarak, DeepSpeech’i CPU’da çalıştırmayı ve GPU’yu diğer derin öğrenme görevleri için kullanmayı tercih edebilirsiniz.
Windows 10/Linux
deepspeech --model deepspeech-0.6.1-models/output_graph.tflite --lm deepspeech-0.6.1-models/lm.binary --trie deepspeech-0.6.1-models/trie --audio audio/2830-3980-0043.wav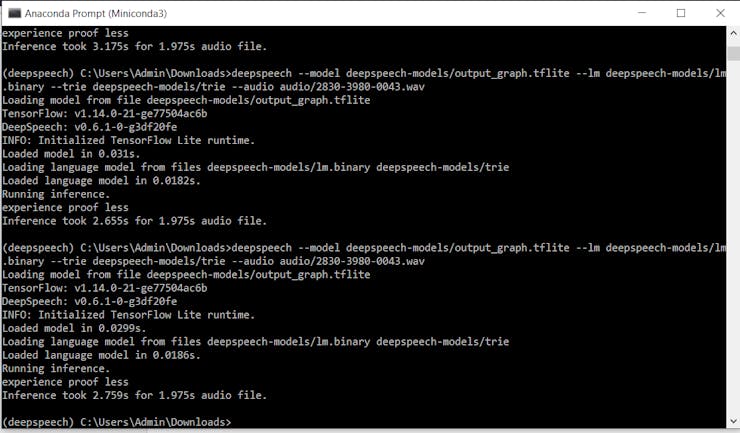
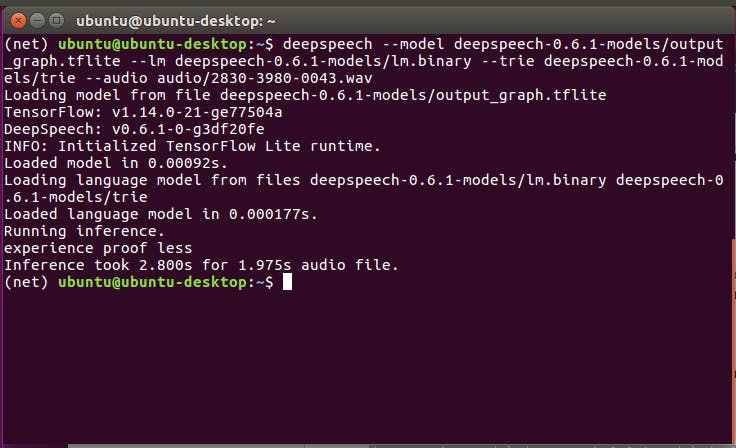
Ya da GPU etkinleştirilmiş sürümü kullanıyorsanız:
deepspeech --model deepspeech-0.6.1-models/output_graph.pbmm --lm deepspeech-0.6.1-models/lm.binary --trie deepspeech-0.6.1-models/trie --audio audio/2830-3980-0043.wav
Gördüğünüz gibi, .tflite modeli modern CPU sistemlerinde gerçek zamanın altında bir performans sergiliyor, bu da çevrimdışı ASR uygulamaları geliştiren insanlar için harika bir haber.
İşte karşılaştırma sonuçları tablosu:
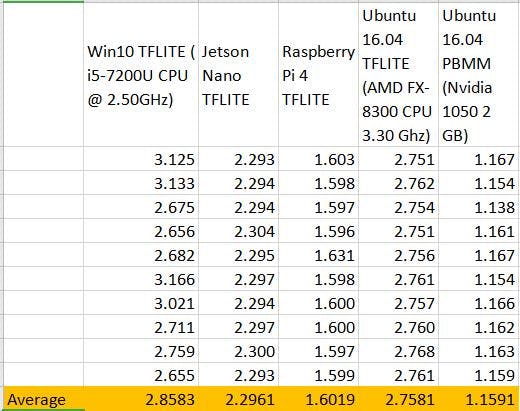
İyi, önceden kaydedilmiş ses örnekleri ile benchmark yaptık, ancak gerçekten gerçek zamanlı transkripsiyon yapmak istiyoruz. Hadi bunu yapalım!
DeepSpeech örneklerini https://github.com/mozilla/DeepSpeech-examples adresinden indirin.
mic_vad_streaming klasörüne gidin ve bağımlılıkları şu şekilde kurun:
pip3 install -r requirements.txtMikrofonu sisteminize bağlayın (ben Raspberry Pi 4 1 GB kullanıyorum). Mikrofon olarak, dizüstü bilgisayarınızdaki dahili mikrofon dahil her türlü mikrofonu kullanabilirsiniz, ancak ses kalitesi sonuçları çok etkiler. Bu demo için, Seeed Studio’dan ReSpeaker USB Mic Array kullanıyorum. 5 metreye kadar uzak alan ses alımını destekler ve aşağıdaki akustik algoritmalar uygulanmıştır: DOA (Geliş Yönü), AEC (Otomatik Eko İptali), AGC (Otomatik Kazanç Kontrolü), NS (Gürültü Bastırma).

python3 ../DeepSpeech-examples/mic_vad_streaming/mic_vad_streaming.py -m ./output_graph.tflite -l lm.binary -t trie -v 3Bu komutu modellerin bulunduğu klasörden çalıştırın. -v argümanı, VAD (Ses aktivite tespiti) eşiğini ayarlamanıza olanak tanır. İşte demo sonuçları.
Peki, harika! Bunu geliştirebilir miyiz? Evet. Cihazımızın sürekli olarak konuşmaları transkribe etmesini istemiyoruz. Gizlilik kabuslarından ve israf edilen elektriğin konuşulmasından bahsedelim.

Dinliyor mu? Yoksa belki de hayır. Açık kaynak değilse asla bilemezsiniz.
Bu nedenle, sözde uyanma kelimesi tespiti uygulamak istiyoruz. DeepSpeech, genel amaçlı bir ASR motorudur ve uyanma kelimeleri için daha hafif ve kısa sesli komutlar için daha doğru bir şey kullanmamız gerekiyor. Raspberry Pi üzerinde sıcak kelime tespiti için iki çerçeve denedim: Snowboy ve Porcupine. İlk çerçeve başarılı bir şekilde çalıştı, ancak yalnızca Python 2’yi destekliyordu… Snowboy’un GitHub deposuna daha yakından bakıldığında, muhtemelen artık aktif bir geliştirme altında olmadığı görülüyor. Porcupine harika çalıştı ve ticari olmayan uygulamalar için ücretsizdir. Bu nedenle, uyanma kelimesi tespitini çalıştıracak ve tespit edildiğinde DeepSpeech ASR ile konuşmayı transkribe etmeye başlayacak küçük bir betik yazdım. “Transkribe etmeyi durdur” anahtar kelimesi transkripte tanındığında transkribe etmeyi durduracaktır. Sonrasında, uyanma kelimesi moduna geri döner.
İşte betiğin sonucu – oldukça düzenli ve tamamen çevrimdışı.
Sonucu kendiniz yeniden üretmek için, dosyaları Porcupine Github adresinden indirin ve aşağıdaki dosya yapısına sahip bir klasör oluşturun (Porcupine kütüphanelerini ve kodunu yeniden dağıtamıyorum, bu yüzden sadece kendi betiğimi Github’a yüklüyorum, klasör yapısıyla birlikte).

Ayrıca resources/util/python/util.py dosyasında bir satırlık değişiklik yapmanız gerekecek:
elif 'rev 3' in model_info:
return 'cortex-a53'Bu, biraz geçici bir yaklaşım, ancak ne yazık ki Porcupine, Raspberry Pi 4’te resmi olarak desteklenmiyor… Oysa Raspberry Pi 3 ile aynı mimariye sahip. Yani “rev 5” ifadesini “rev 3” olarak değiştirmezseniz, başlamayacaktır.
Umarım bu makaleyi beğenmişsinizdir ve sizin için faydalı olmuştur. Bence 2020, güvenilir çevrimdışı NLP ve ASR’nin Edge cihazlarına, telefonlarımıza, akıllı asistanlarımıza ve diğer gömülü elektroniklere geleceği yıl olacak. Bu harekete katılmak isterseniz, Mozilla’nın DeepSpeech Github’ına göz atabilir ve farklı diller veya farklı kelime dağarcığı için kendi modelinizi eğitmeye çalışabilirsiniz. DeepSpeech hakkında gerçekten sevdiğim şey, kullanımı bu kadar kolay olmasının yanı sıra, tamamen açık kaynaklı olması ve katkılara açık olmasıdır.
Bu makalenin donanımı Seeed Studio tarafından nazikçe sağlanmıştır. Kontrol edin
Raspberry Pi 4, ReSpeaker USB Mikrofona ve Seeed Studio mağazasında diğer yapımcı donanımlarını inceleyin!
Daha fazla video ve makale için bizi izlemeye devam edin!