
Bu blog, farklı NVIDIA Jetson cihazlarında çalışan tüm YOLOv8 modellerinin performans ölçümlerinden bahsedecektir. Bu test için özel olarak 3 farklı Jetson cihazı seçtik; bunlar Jetson AGX Orin 32GB H01 Kit, Orin NX 16GB ile donatılmış reComputer J4012 ve Xavier NX 8GB ile donatılmış reComputer J2021dir.
YOLOv8 Nedir?
YOLOv8, Ultralytics tarafından geliştirilen, önceki YOLO sürümlerinin başarısı üzerine inşa edilen, en son teknolojiye sahip (SOTA) bir modeldir ve performansı ve esnekliği artırmak için yeni özellikler ve iyileştirmeler sunar. YOLOv8, hızlı, doğru ve kullanımı kolay olacak şekilde tasarlanmıştır, bu da onu geniş bir nesne tespiti, görüntü segmentasyonu ve görüntü sınıflandırma görevleri için mükemmel bir seçim haline getirir.

YOLOv8 Model Türleri
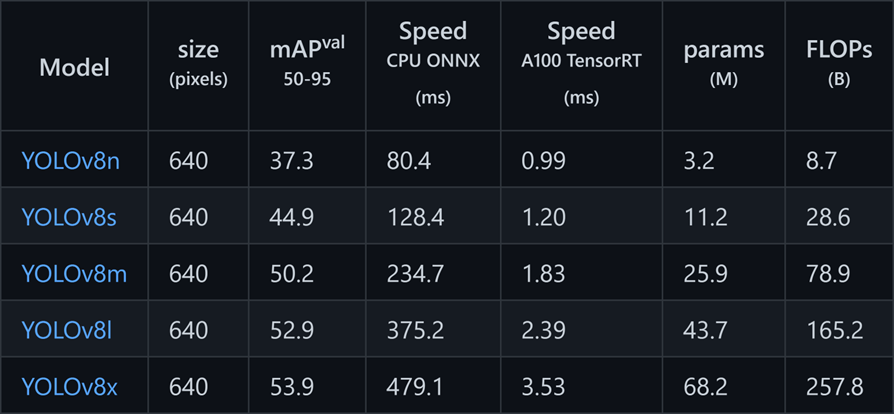
YOLOv8, modelin doğruluğuyla ilişkili parametre sayısına dayanan farklı model türlerine sahiptir. Yani, model ne kadar büyükse, o kadar doğrudur. Örneğin, YOLOv8x en büyük modeldir ve tüm modeller arasında en yüksek doğruluğa sahiptir.
Neden Performans Ölçümü Yapmalıyız?
Performans ölçümleri yaparak, belirli bir model türünün belirli bir cihazda ne kadar çıkarım performansı elde edebileceğinizi öğrenebilirsiniz. Bu, NVIDIA Jetson platformu gibi gömülü cihazlar için daha önemlidir çünkü uygulamanız için kullanmak istediğiniz kesin model türünü biliyorsanız, o modeli çalıştırmak için hangi donanımın uygun olacağına karar verebilirsiniz.
Neden TensorRT Ölçümlerine İhtiyacımız Var?
TensorRT, NVIDIA tarafından geliştirilen, NVIDIA GPU’larda çıkarımı hızlandırmak için bir kütüphanedir. TensorRT, CUDA üzerine inşa edilmiştir ve TensorRT olmadan PyTorch ve ONNX gibi yerel modelleri çalıştırmaya kıyasla birçok gerçek zamanlı hizmet ve gömülü uygulamada 2 ila 3 kat daha hızlı çıkarım sağlayabilir.
Nvidia Jetson Cihazlarında YOLOv8 Kurulumu
Adım 1: Jetson cihazını bu kılavuzda açıklandığı gibi JetPack ile flaşlayın.
Adım 2: Jetson cihazında YOLOv8’i kurmak için yukarıdaki kılavuzun “Gerekli Paketleri Kur” ve “PyTorch ve Torchvision Kur” bölümlerini takip edin.
Nasıl Ölçüm Yapılır?
NVIDIA JetPack ile bir NVIDIA Jetson cihazında SDK bileşenleri ile kurulum yaptığınızda, trtexec adında bir araç olacaktır. Bu araç aslında SDK bileşenleri kurulumu ile birlikte gelen TensorRT içinde yer almaktadır. Bu, kendi uygulamanızı geliştirmeden TensorRT’yi kullanmak için bir araçtır. trtexec aracının üç ana amacı vardır:
- Rastgele veya kullanıcı tarafından sağlanan giriş verileri üzerinde ağları ölçmek.
- Modellerden serileştirilmiş motorlar oluşturmak.
- Yapıcıdan serileştirilmiş zamanlama önbelleği oluşturmak.
Burada trtexec aracını kullanarak farklı parametrelerle modelleri hızlı bir şekilde ölçebiliriz. Ancak öncelikle bir ONNX modeline sahip olmalısınız ve bu ONNX modelini Ultralytics YOLOv8 kullanarak oluşturabiliriz.
Adım 1: Aşağıdaki komutu kullanarak ONNX modelini oluşturun:
yolo mode=export model=yolov8s.pt format=onnxBu, en son yolov8s.pt modelini indirecek ve ONNX formatına dönüştürecektir.
Adım 2: Aşağıdaki gibi trtexec kullanarak motor dosyasını oluşturun:
cd /usr/src/tensorrt/bin
./trtexec --onnx=<path_to_onnx_file> --saveEngine=<path_to_save_engine_file>Örneğin:
./trtexec --onnx=/home/nvidia/yolov8s.onnx --saveEngine=/home/nvidia/yolov8s.engineBu, oluşturulan .engine dosyası ile birlikte performans sonuçlarını aşağıdaki gibi verecektir. Varsayılan olarak, ONNX’i FP32 hassasiyetinde TensorRT ile optimize edilmiş bir dosyaya dönüştürecektir ve çıktıyı aşağıdaki gibi görebilirsiniz.
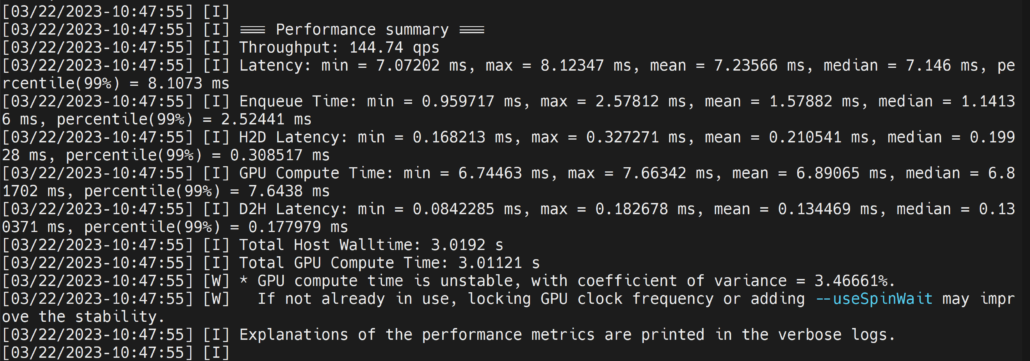
Burada ortalama gecikmeyi 7.2ms olarak alabiliriz, bu da 139FPS’ye denk gelir.
Ancak, daha iyi performans sunan INT8 hassasiyetini istiyorsanız, yukarıdaki komutu aşağıdaki gibi çalıştırabilirsiniz:
./trtexec --onnx=/home/nvidia/yolov8s.onnx --saveEngine=/home/nvidia/yolov8s.engine --int8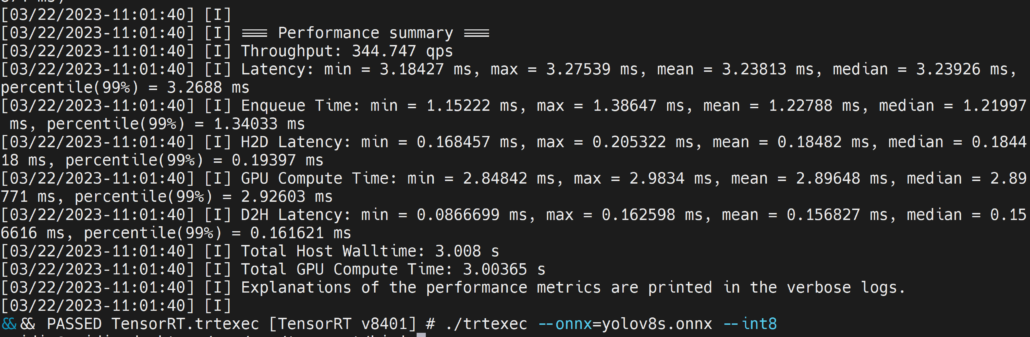
Burada ortalama gecikmeyi 3.2ms olarak alabiliriz, bu da 313FPS’ye denk gelir.
Ayrıca FP16 hassasiyetinde çalıştırmak isterseniz, komutu aşağıdaki gibi çalıştırabilirsiniz:
./trtexec --onnx=/home/nvidia/yolov8s.onnx --saveEngine=/home/nvidia/yolov8s.engine --fp16YOLOv8 modellerinin varsayılan PyTorch sürümündeki performansı kontrol etmek için, çıkarım yapabilir ve gecikmeyi aşağıdaki gibi kontrol edebilirsiniz:
yolo detect predict model=yolov8s.pt source='<>' Burada kaynağı bu sayfadaki tabloda gösterildiği gibi değiştirebilirsiniz.
Ayrıca, bir kaynak belirtmezseniz, varsayılan olarak “bus.jpg” adlı bir resmi kullanacaktır.
Performans Ölçüm Sonuçları
Performans ölçüm sonuçlarına geçmeden önce, ölçüm sürecinde kullandığımız her cihazın AI performansını hızlıca vurgulamak istiyorum.
| Jetson Cihazı | AGX Orin 32GB H01 Kit | Orin NX 16GB ile donatılmış reComputer J4012 | Xavier NX 8GB ile donatılmış reComputer J2021 |
|---|---|---|---|
| AI Performansı | 200TOPS | 100TOPS | 21TOPS |
Artık her seferinde tek bir cihazda YOLOv8 performansını karşılaştırmak için ölçüm grafiklerine bakalım. Tüm ölçümleri 640×640 boyutunda varsayılan PyTorch model dosyası ile gerçekleştirdim ve yukarıda açıklandığı gibi ONNX formatına dönüştürdüm.
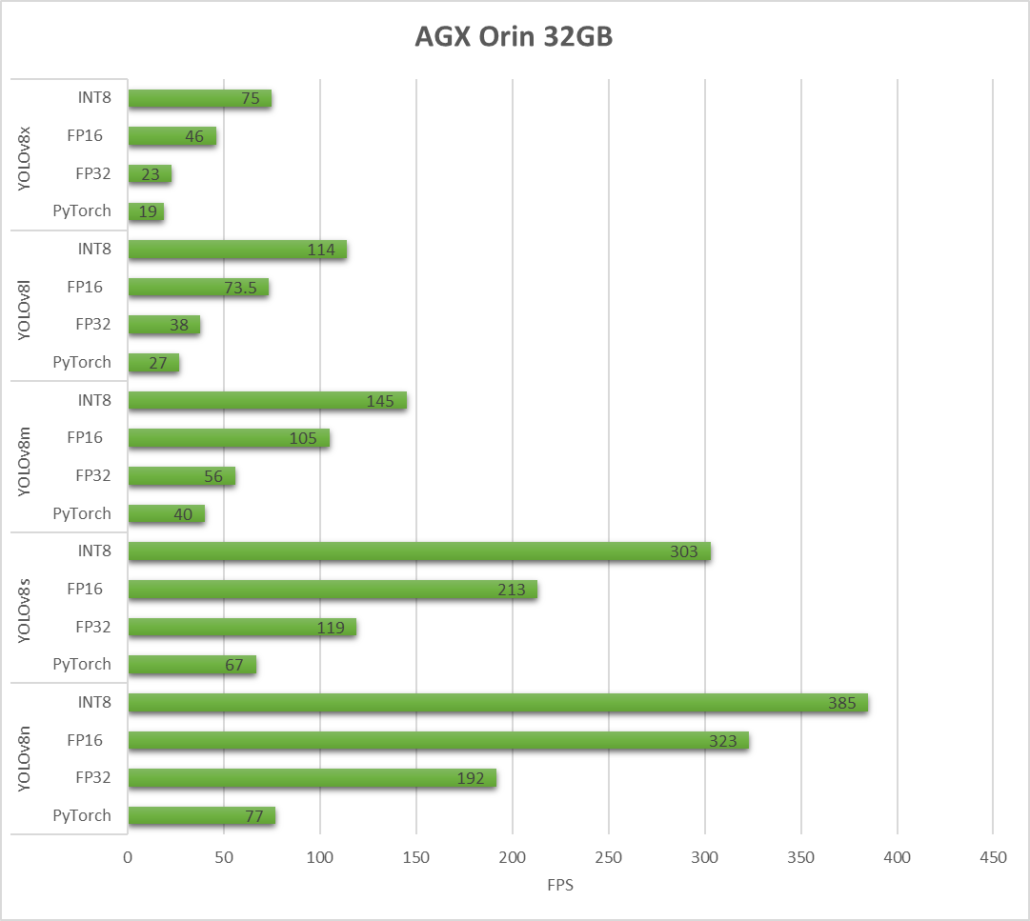
AGX Orin 32GB H01 Kit
Orin NX 16GB ile donatılmış reComputer J4012
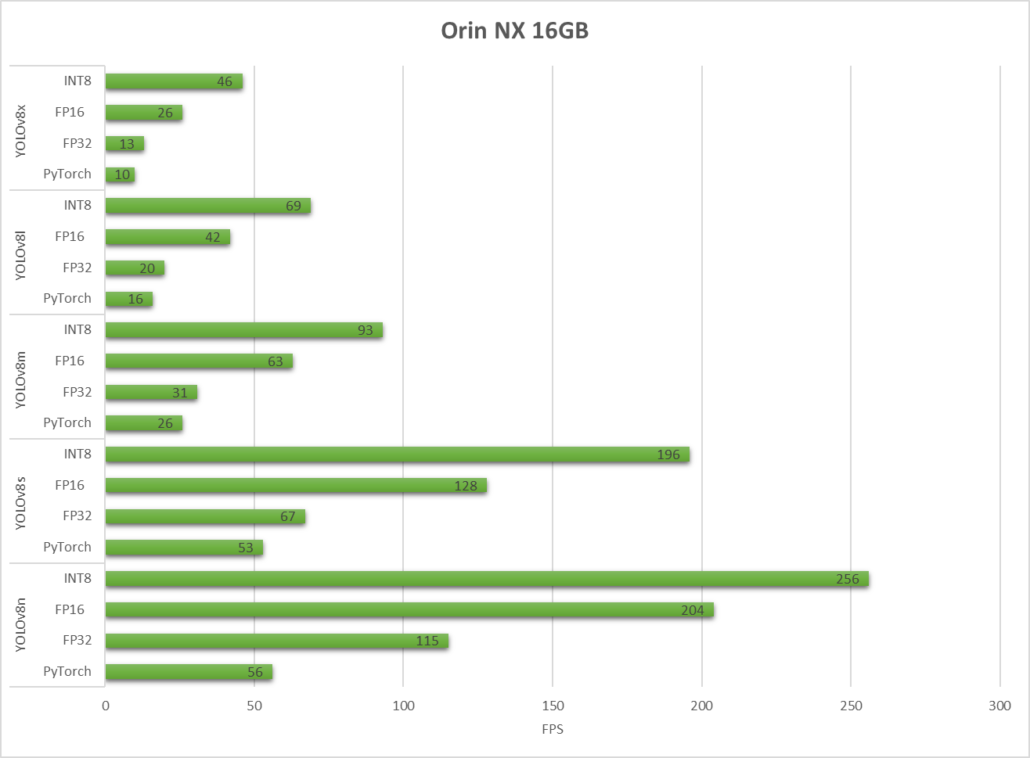
Xavier NX 8GB ile donatılmış reComputer J2021
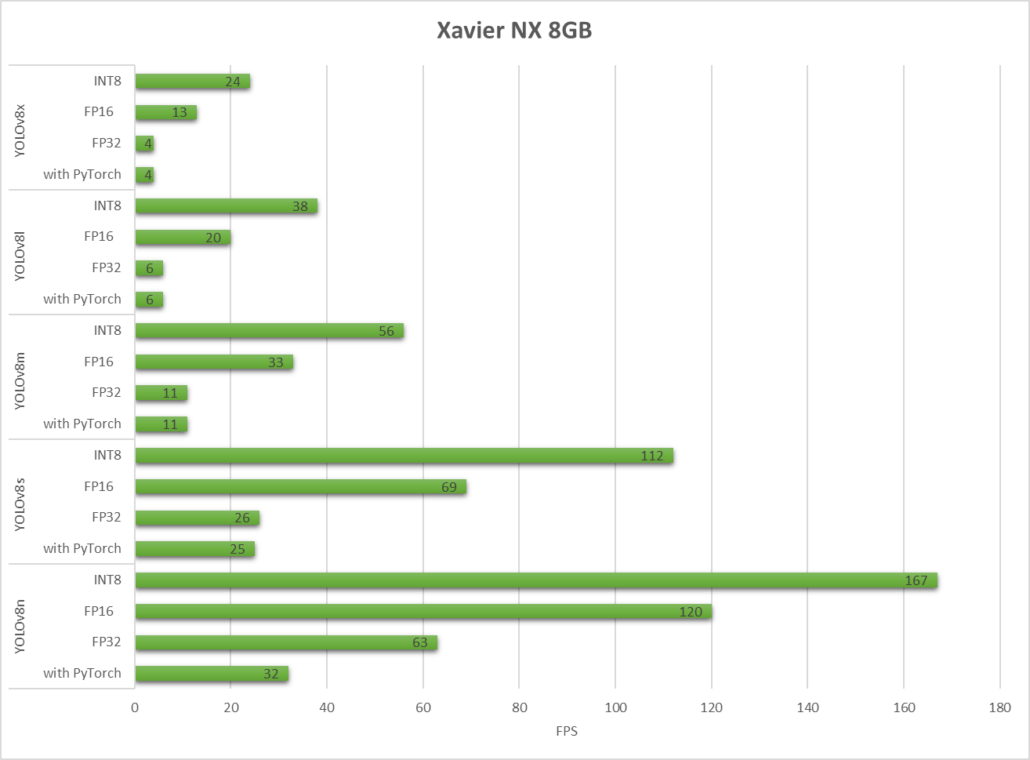
Gördüğümüz gibi, TensorRT önemli bir performans artışı sağlayabilir.
Sonraki aşamada, her bir YOLOv8 modelinin farklı cihazlardaki performansının karşılaştırıldığı benchmark grafiklerine farklı bir perspektiften bakacağız.
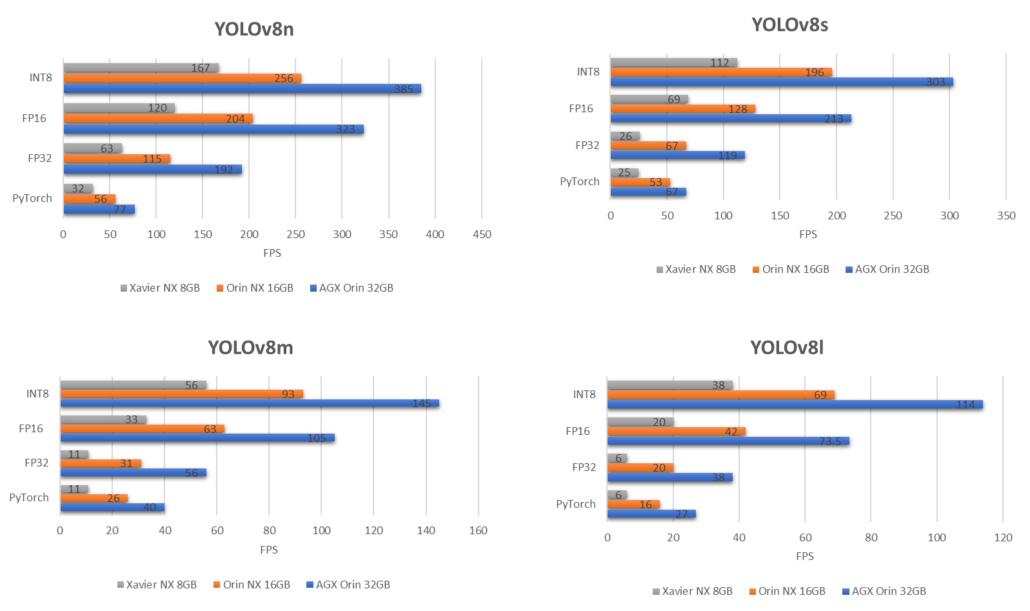
En büyük YOLOv8 modeli olan YOLOv8x’i yukarıdaki 3 cihazda karşılaştırdığımızda, elde ettiğimiz sonuç budur.
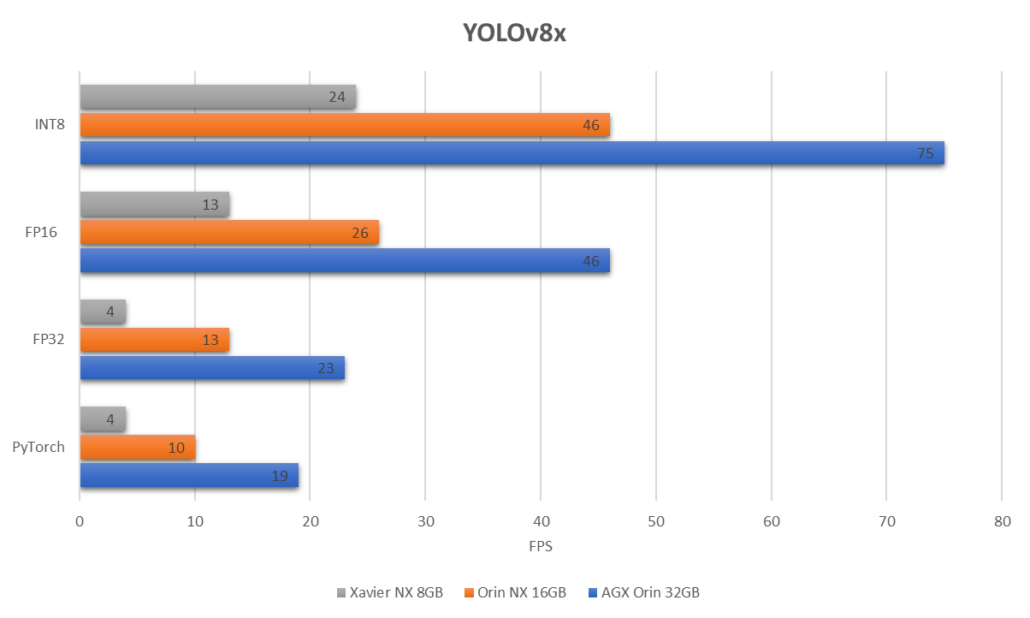
Gördüğünüz gibi, en büyük YOLOv8x modelinde INT8 hassasiyeti ile AGX Orin 32GB üzerinde yaklaşık 75 FPS elde edebiliyoruz, bu da gömülü bir cihaz için oldukça etkileyici!
Sonuç
Yukarıdaki tüm benchmark sonuçlarına göre, NVIDIA Jetson Orin platformu gibi gömülü cihazlarda çıkarım performansının yıllar içinde dramatik bir şekilde arttığı görülüyor ve artık bu tür kompakt cihazlarla sunucu seviyesindeki performansa ulaşma yolunda neredeyse ilerliyoruz!