
Meydan Okuma
Son günlerde, büyük dil modellerinin (LLM’ler) yetenekleri hızla gelişiyor ve donanım sistemlerinin bu büyük modelleri daha karmaşık verileri ve senaryoları çıkarmak için kullandığı IoT dünyasında belirgin bir eğilim görüyoruz.
Sonra, tartışılacak bir sonraki konu – bu nasıl daha ucuz ve verimli hale getirilebilir?
- Nasıl daha ucuz hale getirilebilir? Büyük modellerin sıkça çağrılması ve uzun süreli kullanımı pahalıdır;
- Bekleme süresi azaltılabilir mi? Büyük bir modele veri göndermekten çıkarım sonuçlarını almak yaklaşık 10-40 saniye sürebilir.
İki Yenilikçi Çözüm
1. TinyML’in büyük modelleri etkinleştirmek için bir tetikleme mekanizması olarak kullanılması
- Anahtar Kare Filtreleme: LLM’ye sürekli veri beslemek yerine, bir tinyML modeli donanım cihazında işlenerek giriş akışından anahtar kareleri veya kritik veri noktalarını tanımlayabilir. Bu anahtar kareler, görüntüler, bir ses kesiti veya diyelim ki – 3 eksenli ivmeölçerden önemli dalgalanmalar olabilir. Sadece bu seçilen veri noktaları derinlemesine analiz için büyük modele iletilir, böylece önemli veriler önceliklendirilir ve gereksiz işleme ortadan kaldırılır.
- Azaltılmış Token Kullanımı: Anahtar karelere odaklanarak, LLM’ye gönderilen token sayısı en aza indirilir, bu da önemli maliyet tasarruflarına yol açar. Bu yaklaşım ayrıca, temel verilere odaklanarak genel yanıt süresini hızlandırır.
Nvidia GTC konferansında Pratik Gösterim
Bu yaklaşımın etkinliğini GTC’deki TinyML+LLaVA (Yerel Dil Modeline Dayalı Video Analitiği) demosunda gösterdik. İki cihaz kombinasyonu sergiledik:
- Kurulum 1: bir USB kamera + Nvidia Jetson Orin AGX
Bu standart sistemde, bir USB kamera doğrudan LLaVA’yı çalıştıran bir AGX’e bağlandı ve sürekli olarak her yakalanan kareyi işledi. - Kurulum 2: SenseCAP Watcher + Nvidia Jetson Orin AGX
Bu sistem, sensör bir kişiyi tespit ettiğinde yalnızca LLaVA analizini tetikleyen bir TinyML görsel sensör kullandı ve böylece kediler gibi alakasız kareleri önledi.
TinyML yapılandırması, doğrudan LLM çağrısı kurulumuna kıyasla CPU, RAM, bant genişliği, GPU kullanımı ve enerji tüketiminde önemli azalmalar gösterdi.
İşte demo videosu.
“““html
2. LLM’lerin yerel donanımlarda yerelleştirilmesi
Maliyetleri optimize etmenin ve gecikmeyi azaltmanın bir diğer yaklaşımı, LLM’leri yerel PC’lerde veya gömülü bilgisayarlarda çalıştırmaktır – bu, cihazda işleme anlamına gelir. Bu yaklaşım birkaç avantaj sunar:
- Maliyet azaltma: Veri transferi ve bulutta uzaktaki çevrimiçi LLM’leri çağırma ile ilişkili bant genişliği ve API kullanım ücretlerini ortadan kaldırır.
- Düşük gecikme: LLM’lerden sonuç almak için geçen süre, ağ gecikmeleri ve çıkarım süresinden oluşur. Yerel LLM’ler kullanarak, ağ gecikmesi en aza indirilir. Çıkarım süresini daha da azaltmak için, Jetson Orin AGX gibi daha güçlü bilgisayarlar tercih edilerek daha hızlı yanıt süreleri elde edilebilir, bu süre potansiyel olarak 3 saniyeye kadar düşebilir.
- Geliştirilmiş gizlilik: LLM’leri yerel olarak çalıştırmak, verilerinizin kamuya açık AI platformlarıyla paylaşılmadığını garanti eder, böylece verileriniz üzerinde sahiplik ve kontrol sağlarsınız.
Pek çok büyük model artık yerel dağıtımı destekliyor, örneğin Llama, LLaVA ve Whisper.

Maliyet Karşılaştırması: GPT-4 Turbo vs Yerel LLaVA
Peki, ne zaman çevrimiçi büyük bir model tercih etmelisiniz ve ne zaman yerel bir kurulum daha iyidir?
OpenAI’nin GPT-4 Turbo API’si ile yerel bir LLaVA kurulumu arasında basit bir maliyet karşılaştırması yaptık. Bu durumda reComputer J4012 kullanıldı.
Her sistem, dakikada bir kez 640px x 480px boyutunda bir görüntü işledi. Amacımız, GPT-4 Turbo API’sini kullanmanın toplam maliyetinin, reComputer J4012 üzerindeki yerel LLaVA kurulumunun bir kerelik satın alma fiyatını aşacağı zamanı belirlemekti.
Maliyet detayları:
- OpenAI API: $0.005 her görüntü analizi (640×480 px) için OpenAI’nin fiyatlandırma bilgilerine göre.
- Yerel LLaVA: $899 reComputer J4012 için – NVIDIA Jetson Orin NX 16GB modülü (bir kerelik maliyet). Yerel bir ağda çalıştığı için, bant genişliği maliyetleri veya API kullanım ücretleri yoktur, tek masraf J4012 cihazının satın alınmasıdır.

Bu kaba hesaplamaya dayanarak, GPT-4 Turbo’yu beş ay kullanmak yaklaşık $1080 maliyetinde olacaktır, bu da J4012’nin fiyatını aşmaktadır.
Bu nedenle, yalnızca kısa süreli veya seyrek kullanım için LLM’lere ihtiyacınız varsa, kamuya açık bir LLM tercih etmek uygundur.
“`
Ancak, eğer bunları uzun süreli kullanmanız gerekiyorsa ve maliyetlere duyarlıysanız, bunları yerel bir bilgisayara kurmak çok etkili bir stratejidir. Daha yüksek çözünürlüklü görüntüler daha yüksek maliyetler doğurur, bu da yerel dağıtımın maliyet avantajını daha belirgin hale getirir.
Peki, yerelleştirilmiş LLM’lerin çıkarım hızı nasıl?
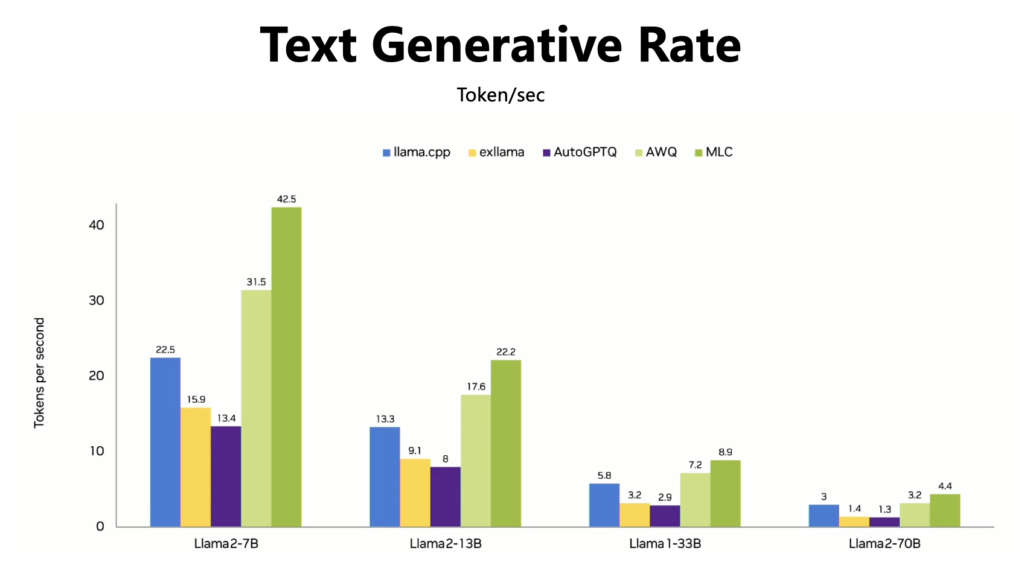
Aşağıdaki grafiğe bakın; burada çeşitli popüler Llama modellerini nicelendirip, ardından bunları Jetson Orin AGX 64GB üzerinde test ederek çıkarım hızlarını karşılaştırdık.
İnsan okuma hızını bir kıyaslama noktası olarak alırsak, bu genellikle saniyede 3-7 token arasında değişir, o zaman saniyede 8 token’ı aşan bir çıkarım hızı oldukça yeterli olacaktır. Görünüşe göre, bu donanımda büyük bir 13B model çalıştırmak mümkün ve 7B model için performans daha da üstün.
Ancak, 33B gibi daha büyük modeller çalıştırmanız gerekiyorsa ve çıkarım hızı için belirli gereksinimleriniz varsa, daha güçlü bir bilgisayar tercih etmeniz önerilir.
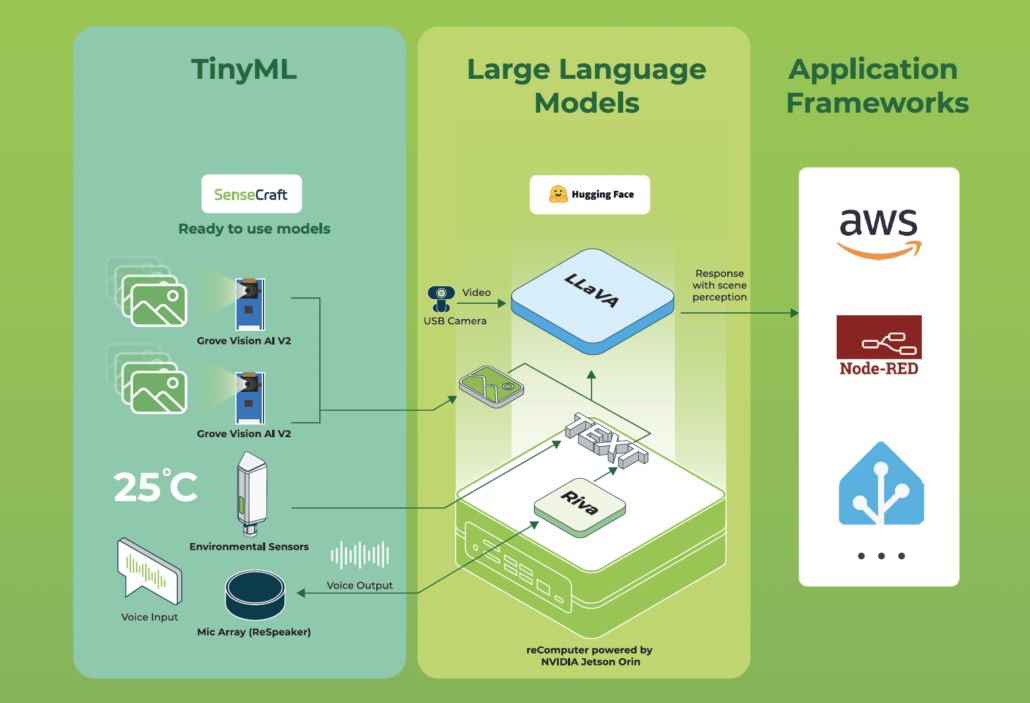
Seeed Ürünlerini Keşfetmek: TinyML + Yerel Üretken AI Mimarisi Desteği
Seeed ürünleri iki ana kategoriye ayrılmaktadır: AI Sensörleri ve Kenar Bilgisayarları.
Bu ürünler, gelişmiş ve entegre çözümler sağlamak için Seeed SenseCraft yazılım paketleri ile desteklenmektedir.
AI Sensörleri
AI sensörlerinin temsilci ürünleri SenseCAP Watcher, Grove Vision AI Sensor V2 ve XIAO‘dur.
SenseCAP Watcher – daha akıllı alanlar için fiziksel bir LLM ajanıdır. Çeşitli tinyML ve Gen AI modellerini yerel olarak destekler. Belirli bir alanı izlemeye yardımcı olabilir, sizin için önemli olan herhangi bir aktiviteyi tespit edebilir ve SenseCraft APP veya kendi uygulamanız üzerinden size zamanında bildirimde bulunabilir.
Dünyanın ilk fiziksel LLM ajanı olarak daha akıllı alanlar için SenseCAP Watcher:
- Belirli bir alanı izleyebilir.
- Belirlediğiniz hedeflerle etkileşimde bulunabilir.
- Önemli olayları tespit edebilir ve bildirimde bulunabilir.
Sadece “birini gördüğünde bana haber ver” gibi ses / APP komutları verin ve Watcher, bu tür olaylar gerçekleştiğinde sizi bilgilendirecektir. Ama bu sadece hedefleri tespit etmekle kalmaz, LLM’nin yeteneklerini kullanarak davranışları ve durumları analiz eder. Örneğin, bir kişiyi + kırmızı bir tişört giyen veya bir köpeğin peçeteleri parçaladığını tespit etmek gibi.
Bu ürün şimdi Kickstarter’da CANLI. Bize destek olmak için buraya tıklayın ve erken kuş fiyatını şimdi alın.
“`html

Grove Vision AI Sensörü V2 – ana kontrolcünüze (Arduino / Raspberry Pi gibi) vektör verileri için özel bir alt işlemci eklemek istiyorsanız en İYİ seçenektir. Arm Cortex-M55 & Ethos-U55 ile donatılmıştır ve mevcut Cortex-M tabanlı sistemlere göre ML performansında 480 kat artış sağlar.

Ya da kendi AI sensörlerinizi XIAO – tinyML MCUs. ile oluşturabilirsiniz.

Kenar Bilgisayarları
Bu kategorideki temsilci ürünler reComputer Nvidia Jetson serisi. Yerel Üretken AI (Gen AI) çalıştırma kapasitesine sahip olup, giriş seviyesi 40 TOPS J3011’den yüksek performanslı 275 TOPS J50’ye kadar çeşitlilik göstermektedir.
Daha fazla bilgi için burayatıklayın ve bu ürün serisi hakkında daha fazla bilgi edinin.
“““html


Paylaşılan içgörülerin ve bilgilerin aydınlatıcı ve ilham verici olduğunu umuyorum.
Eğer paylaşmak istediğiniz düşünceleriniz, deneyimleriniz veya sorularınız varsa, lütfen aşağıda yorum yapmaktan çekinmeyin.