
28 Şubat 2024’te güncellendi
Bu, TinyML eğitim serisinin ikinci makalesi ve bugün Wio Terminal ve Edge Impulse ile bir ses sahnesi sınıflandırıcısını nasıl eğitip dağıtacağınızı öğreteceğim. Daha fazla ayrıntı ve video eğitimi için ilgili videoyu izleyin!
Öncelikle ses sinyali işleme hakkında biraz arka plan bilgisi. Eğer doğrudan eyleme geçmek istiyorsanız, bir sonraki bölüme geçebilirsiniz! Ya da geçmeyin – ses işleme hakkında zaten bir şeyler bildiğimi düşünüyordum, ancak bu makaleyi yaparken kendim de birçok yeni şey öğrendim.
ML için ses işleme
Ses, bir gaz, sıvı veya katı gibi bir iletim ortamı aracılığıyla yayılan (veya hareket eden) bir titreşimdir.

Ses kaynağı, çevresindeki ortam moleküllerini iter, bu moleküller yanlarındaki molekülleri iter ve bu böyle devam eder. Diğer bir nesneye ulaştıklarında, o da hafifçe titreşir – bu prensibi mikrofonlarda kullanıyoruz. Mikrofon membranı, ortam molekülleri tarafından içe doğru itilir ve ardından orijinal konumuna geri döner.
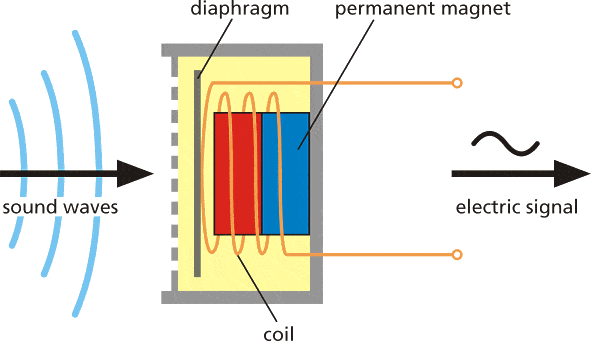
Bu, devrede alternatif akım üretir; burada voltaj, ses amplitüdü ile orantılıdır – ses ne kadar yüksekse, membranı o kadar çok iter ve dolayısıyla daha yüksek voltaj üretir. Bu voltajı analogdan dijitale çevirici ile okur ve eşit aralıklarla kaydederiz – bir saniyede ses ölçümü yaptığımız sayı, örneğin 8000 Hz örnekleme hızı, saniyede 8000 kez ölçüm yapmak anlamına gelir. Örnekleme hızı, ses kalitesi için oldukça önemlidir – eğer çok yavaş örnek alırsak, önemli detayları kaçırabiliriz. Dijital olarak ses kaydetmek için kullanılan sayılar da önemlidir – kullanılan sayı aralığı ne kadar büyükse, orijinal sesin o kadar fazla “nüansını” koruyabiliriz. Buna ses bit derinliği denir – 8-bit ses ve 16-bit ses gibi terimleri duymuş olabilirsiniz. İşte bu tam olarak etiketinde yazdığı gibidir – 8-bit ses için, 0 ile 255 arasında değişen işaretsiz 8-bit tamsayılar kullanılır. 16-bit ses için ise, -32.768 ile 32.767 arasında değişen işaretli 16-bit tamsayılar kullanılır. Sonuç olarak, daha büyük sayılar sesin yüksek kısımlarına karşılık gelen bir dizi sayıya sahibiz ve bunu şu şekilde görselleştirebiliriz.
Ancak bu ham ses temsili ile pek bir şey yapamayız – evet, parçaları kesip yapıştırabiliriz veya sesin tonunu artırabiliriz, ancak sesi analiz etmek için bu, oldukça hamdır. İşte burada Fourier dönüşümü, Mel ölçeği, spektrogramlar ve cepstrum katsayıları devreye giriyor. Fourier dönüşümü hakkında internette birçok materyal var, kişisel olarak betterexplained.com’daki bu makaleyi ve 3Blue1Gray’den bir videoyu gerçekten seviyorum – FFT hakkında daha fazla bilgi edinmek için bunlara göz atın. Bu makalenin amacı için, Fourier dönüşümünü bir sinyali bireysel frekanslarına ve frekansın amplitüdüne ayırmamıza olanak tanıyan matematiksel bir dönüşüm olarak tanımlayacağız.
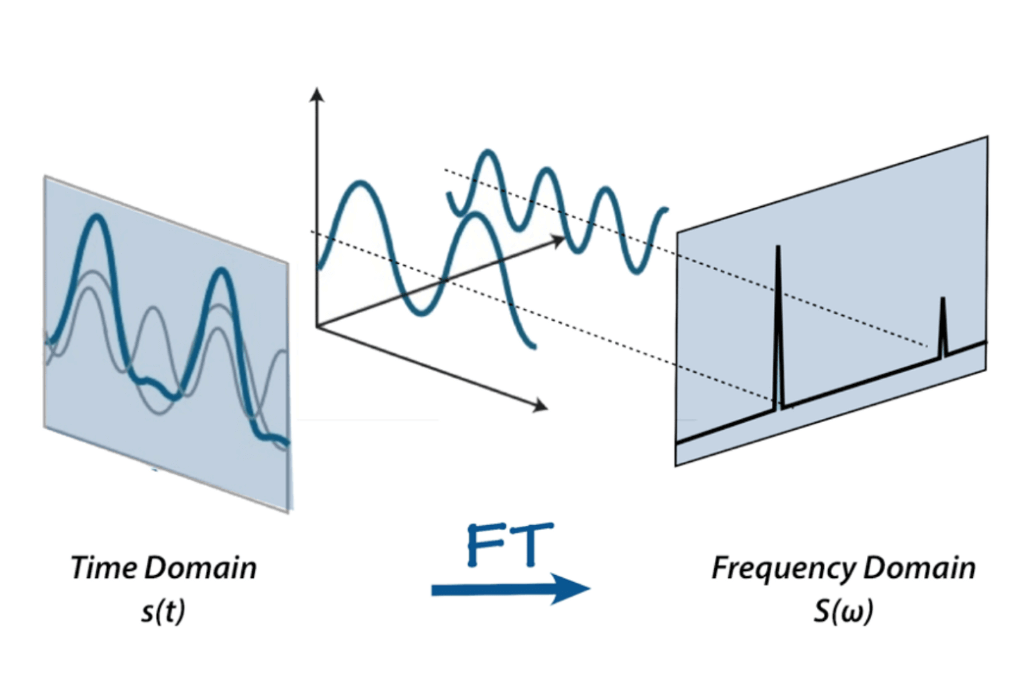
Ya da betterexplained makalesinde belirtildiği gibi – verilen bir smoothie, tarifi çıkarır. Fourier dönüşümünü uyguladıktan sonra sesimiz böyle görünür – daha yüksek çubuklar, daha büyük amplitüdlü frekanslara karşılık gelir.
Harika! Artık ses sinyali ile daha ilginç şeyler yapabiliriz – örneğin, ses dosyasını sıkıştırmak için en az önemli frekansları ortadan kaldırmak veya gürültüyü ya da belki sesin sesini kaldırmak gibi. Ancak bu, ses ve konuşma tanıma için hala yeterince iyi değil – Fourier dönüşümünü yaparak zaman alanı bilgisinin tamamını kaybediyoruz, bu da insan konuşması gibi periyodik olmayan sinyaller için iyi değildir. Ancak biz akıllı insanlarız ve sinyal örneği üzerinde Fourier dönüşümünü birden fazla kez alıyoruz, temelde onu dilimleyip ardından birden fazla Fourier dönüşümünden verileri tekrar birleştiriyoruz ve bunu spektrogram biçiminde yapıyoruz.
Burada x ekseni zamanı, y ekseni frekansı ve bir frekansın amplitüdü bir renk aracılığıyla ifade edilir; daha parlak renkler, daha büyük amplitüde karşılık gelir.
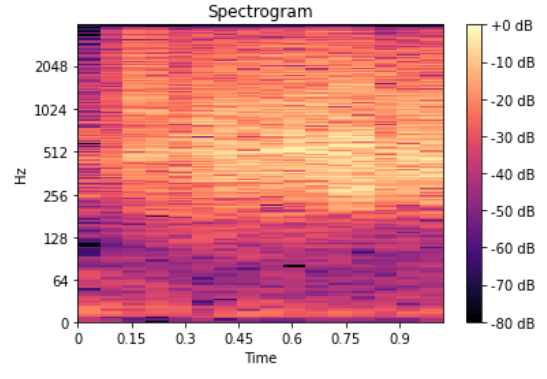
Çok iyi! Şimdi ses tanıma yapabilir miyiz? Hayır! Evet! Belki!
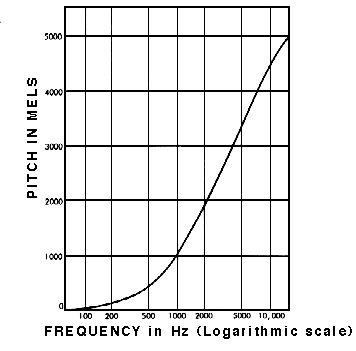
Normal bir spektrogram, insan kulağının duyabileceği sesleri tanımakla ilgileniyorsak çok fazla bilgi içeriyor. Araştırmalar, insanların frekansları lineer bir ölçekle algılamadığını göstermiştir. Düşük frekanslarda farkları tespit etmede daha iyiyiz, yüksek frekanslarda ise daha zorlanıyoruz. Örneğin, 500 ve 1000 Hz arasındaki farkı kolayca ayırt edebiliriz, ancak 10.000 ve 10.500 Hz arasındaki farkı ayırt etmekte zorlanırız, oysa iki çift arasındaki mesafe aynıdır.
1937’de Stevens, Volkmann ve Newmann, ton birimi önerdiler; böylece tonlardaki eşit mesafeler dinleyiciye eşit uzaklıkta geliyordu. Buna mel ölçeği denir.
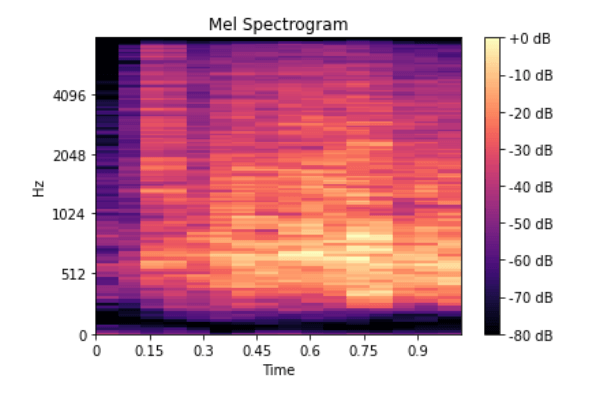
Bir mel spektrogramı, frekansların mel ölçeğine dönüştürüldüğü bir spektrogramdır.
Konuşmayı tanımak için daha fazla adım var – örneğin, yukarıda bahsettiğim cepstrum katsayıları – bunları serinin ilerleyen videolarında tartışacağız. Nihayet pratik uygulamaya başlama zamanı.
Eğitim verilerini toplayın
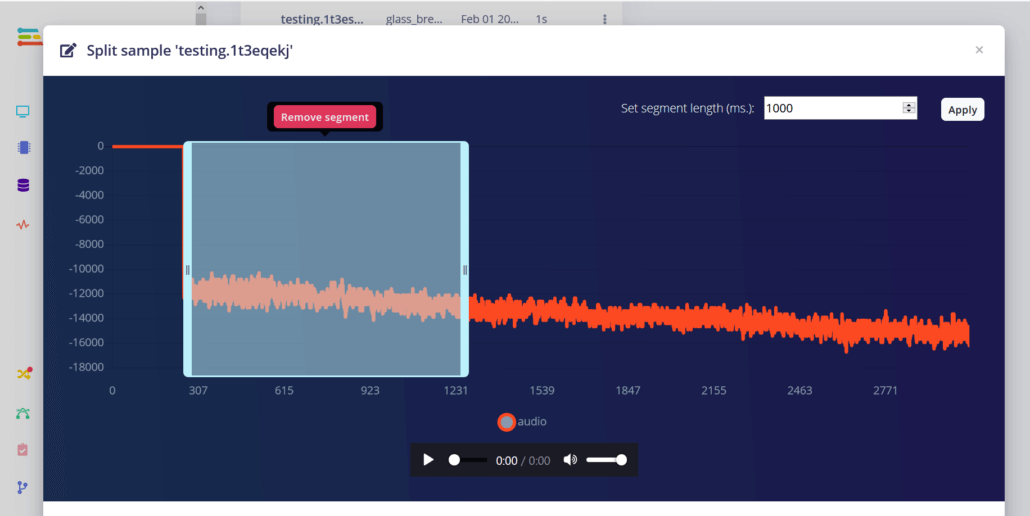
Serinin son videosunda, verileri toplamak için edge-impulse-cli’nin veri iletim aracını kullandık (bunu serinin ilk makalesinde nasıl kuracağınızı görebilirsiniz). Ne yazık ki, ses sinyali için aynı şeyi yapamayız, çünkü veri iletim aracının maksimum sinyal frekansı 370 Hz ile sınırlıdır – ses sinyali için çok düşük. Bunun yerine mikrofon desteği olan Wio Terminal Edge Impulse yazılımının yeni bir sürümünü indirin ve cihazınıza yükleyin. Daha sonra Edge Impulse platformunda yeni bir proje oluşturun, edge-impulse veri alma hizmetini başlatın.
edge-impulse-daemon
Sonra kimlik bilgilerinizle giriş yapın ve yeni oluşturduğunuz bir projeyi seçin. Veri Toplama sekmesine gidin ve veri örnekleri almaya başlayabilirsiniz. 4 veri sınıfımız var ve her sınıf için 10 örnek kaydedeceğiz, her biri 3000 milisaniye sürecek. Ben dizüstü bilgisayardan çalınan sesleri kaydedeceğim (arka plan sınıfı hariç), eğer gerçek sesleri kaydetme fırsatınız varsa, bu daha iyi olur. 40 örnek oldukça az, bu yüzden biraz daha veri yükleyeceğiz. Sesleri YouTube’dan indirdim, 8000 Hz’ye yeniden örnekledim ve basit bir dönüştürücü betiği ile .wav formatında kaydettim – bunu çalıştırmak için pip ile librosa’yı yüklemeniz gerekecek.
import librosa
import sys
import soundfile as sf
input_filename = sys.argv[1]
output_filename = sys.argv[2]
data, samplerate = librosa.load(input_filename, sr=8000) # 44.1kHz'den 8kHz'ye düşür
print(data.shape, samplerate)
sf.write(output_filename, data, samplerate, subtype='PCM_16')Sonra tüm ses örneklerini kesip yalnızca “ilginç” parçaları bıraktım – bunu arka plan hariç her sınıf için yaptım.
Veri toplama tamamlandıktan sonra, işleme bloklarını seçme ve sinir ağı modelimizi tanımlama zamanı geldi.
Veri işleme ve Model eğitimi
İşleme blokları arasında üç tanıdık seçenek görüyoruz – yani Ham, Spektral Analiz, bu esasen sinyalin Fourier dönüşümüdür, Spektrogram ve MFE (Mel-Frekans Enerji bankaları) – bunlar daha önce tanımladığım ses işleme dört aşamasına karşılık geliyor!
Deney yapmayı seviyorsanız, verileriniz üzerinde hepsini denemeyi deneyebilirsiniz, belki Ham hariç, çünkü bu küçük sinir ağımız için çok fazla veri olacaktır. Bu görev için en iyi seçenek olan MFE veya Mel-Frekans Enerji bankaları ile devam edeceğim. Özellikleri hesapladıktan sonra, NN sınıflandırıcı sekmesine gidin ve uygun bir model mimarisi seçin. İki seçeneğimiz var: 1D Conv ve 2D Conv kullanmak. Her ikisi de çalışacak, ancak mümkünse her zaman daha küçük bir model tercih etmeliyiz, çünkü bunu gömülü bir cihaza dağıtmak isteyeceğiz. 4 farklı deney yaptım, MFE ve MFCC özellikleri ile 1D Conv/2D Conv ve sonuçları bu tabloda. En iyi model, MFE işleme bloğu ile 1D Conv ağıydı. MFE parametrelerini (özellikle stride’ı 0.02’ye artırarak ve düşük frekansı 0’a düşürerek) ayarlayarak, doğruluğu varsayılan parametreler için %75’ten aynı veri kümesinde %85’e çıkardım.
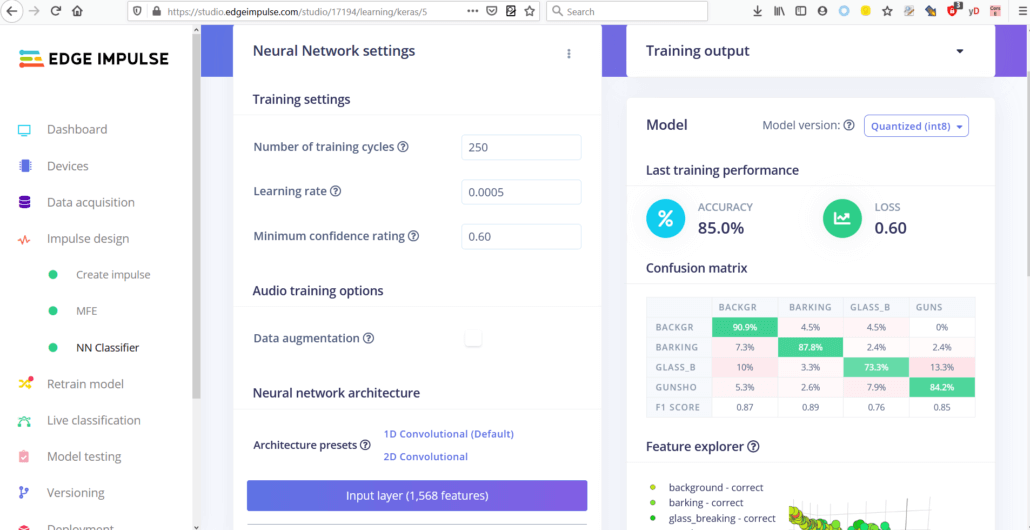
Eğitilmiş modeli buradan bulabilir ve kendiniz test edebilirsiniz. Havlama ve silah seslerini arka plandan ayırt etmede iyi olsa da, cam kırılması sesinin tespiti, canlı sınıflandırma ve cihaz üzerindeki testlerde oldukça düşük bir doğruluk gösterdi. Bunun 8000 Hz örnekleme hızından kaynaklandığını düşünüyorum – kayıtta mevcut olan en yüksek frekans 4000 Hz ve cam kırılması çok fazla yüksek frekanslı gürültü içeriyor, bu da bu belirli sınıfı diğerlerinden ayırt etmeye yardımcı olabilir.
Dağıtım
Modelimizi elde ettikten ve eğitimdeki doğruluğundan memnun kaldıktan sonra, yeni veriler üzerinde Live classification sekmesinde test edebiliriz ve ardından Wio terminaline dağıtabiliriz. Bunu Arduino kütüphanesi olarak indireceğiz, Arduino kütüphaneleri klasörüne koyacağız ve mikrofon çıkarım demosunu açacağız. Demo, Arduino Nano 33 BLE’ye dayanmaktadır ve PDM kütüphanesini kullanmaktadır. Wio Terminal’in nispeten basit mikrofon devresi nedeniyle ve bu sefer işleri gerçekten basit tutmak için, yalnızca analogRead fonksiyonunu ve zamanlama için delayMicroseconds kullanacağız.
static bool microphone_inference_record(void)
{
inference.buf_ready = 0;
inference.buf_count = 0;
if (inference.buf_ready == 0) {
for(int i = 0; i < 8001; i++) {
inference.buffer[inference.buf_count++] = map(analogRead(WIO_MIC), 0, 1023, -32768, 32767);
delayMicroseconds(sampling_period_us);
if(inference.buf_count >= inference.n_samples) {
inference.buf_count = 0;
inference.buf_ready = 1;
break;
}
}
}
return true;
}Burada büyük bir uyarı var – bu ses kaydetmenin doğru yolu değil. Normalde ses örneklemesi için zamanlama yapmak üzere kesmeler kullanırız, ancak kesmeler kendisi büyük bir konu ve videoyu bitirmenizi istiyorum. Bu yüzden bunu (MFCC açıklamasıyla birlikte) konuşma tanıma ile ilgili sonraki bir makaleye bırakacağız.
Örnek kodunu yükledikten sonra, bu Github deposunda bulabilirsiniz, Seri monitörü açın ve her sınıf için olasılıkları yazdırıldığını göreceksiniz. Doğruluğu kontrol etmek için bazı sesler çalın veya köpeğinizi havlatın! Ya da yukarıdaki videodaki demo’yu izleyin.
Blynk ile Mobil Bildirimler
Harika çalışıyor, ama çok pratik değil – demek istediğim, eğer ekranı görebiliyorsanız, muhtemelen sesi kendiniz de duyabiliyorsunuz. Wio Terminal’in İnternete bağlanabilmesi sayesinde, bu basit demoyu alıp Blynk ile gerçek bir IoT uygulamasına dönüştürebiliriz.

Blynk, donanım projelerinizi iOS ve Android cihazlarınızdan kontrol etmek ve izlemek için hızlı bir şekilde arayüzler oluşturmanıza olanak tanıyan bir platformdur. Bu durumda, Wio Terminal herhangi bir ses tespit ettiğinde telefonumuza bildirim göndermek için Blynk’i kullanacağız.
Blynk ile başlamak için, uygulamayı indirin, yeni bir hesap kaydedin ve yeni bir proje oluşturun. İçine bir push notification öğesi ekleyin ve oynat düğmesine basın. Wio terminal için, Seeed_Arduino_rpcWiFi, Seeed_Arduino_rpcUnified, Seeed_Arduino_mbedtls ve Seeed_Arduino_FS kütüphanelerini yükleyin. Ardından, Blynk ile basit bir push buton örneği deneyin – WiFi SSID, şifre ve Blynk API token’ınızı değiştirdiğinizden emin olun.
#define BLYNK_PRINT Serial
#include <rpcWiFi.h>
#include <WiFiClient.h>
#include <BlynkSimpleWioTerminal.h>
char auth[] = "token";
char ssid[] = "ssid";
char pass[] = "password";
void checkPin()
{
int isButtonPressed = !digitalRead(WIO_KEY_A);
if (isButtonPressed) {
Serial.println("Butona basıldı.");
Blynk.notify("Yaaay... butona basıldı!");
}
}
void setup()
{
Serial.begin(115200);
Blynk.begin(auth, ssid, pass);
pinMode(WIO_KEY_A, INPUT_PULLUP);
}
void loop()
{
Blynk.run();
checkPin();
}Eğer kod derlenirse ve test başarılı olursa (Wio Terminal’daki sol üst butona basmak telefonunuzda bir push bildirimi oluşturuyorsa), o zaman bir sonraki aşamaya geçebiliriz.
Tüm sinir ağı çıkarım kodunu ayrı bir fonksiyona taşıyacağız ve bunu loop() fonksiyonunda Blynk.run()’dan hemen sonra çağıracağız. Daha önce yaptığımız gibi, sinir ağı tahmin olasılıklarını kontrol ediyoruz ve eğer belirli bir sınıf için eşik değerinden yükseklerse, Blynk.notify() fonksiyonunu çağırıyoruz, bu da tahmin edebileceğiniz gibi mobil cihazınıza bir bildirim gönderiyor. NN çıkarımı + Blynk bildirimi için tam kodu buradan bulabilirsiniz.
Ve voila, tehlikeli durumlar hakkında insanları uyarmak için kullanılabilecek çalışan bir ML on the Edge IoT uygulamamız var! Geliştirilebilecek birkaç şey var – ve geliştirilecek, en önemlisi sürekli ses örnekleme ve daha yüksek örnekleme hızı ile ses kalitesini artırmak.
Kendi ses setinizle deneyin. Eğer yaparsanız, geri bildiriminizi video veya makale yorumlarında paylaşın! Daha fazla makale için bizi takipte kalın!
TinyML projeniz için en iyi aracı seçin
Grove – Vision AI Modülü V2
Himax WiseEye2 HX6538 işlemcisi ile güçlendirilmiş, MCU tabanlı bir görsel AI modülüdür. rm Cortex-M55 ve Ethos-U55 özelliklerine sahiptir. vektör veri işleme için ince bir şekilde optimize edilmiş Arm Helium teknolojisini entegre eder ve şunları sağlar:
- Ödüllü düşük güç tüketimi
- DSP ve ML yeteneklerinde önemli bir artış
- Pil ile çalışan uç nokta AI uygulamaları için tasarlanmıştır

Tensorflow ve Pytorch çerçevelerini destekleyerek, kullanıcıların Seeed Studio’dan hem hazır hem de özel AI modellerini dağıtmasına olanak tanır. Ayrıca, modül IIC, UART, SPI ve Type-C gibi bir dizi arayüz sunarak, Seeed Studio XIAO, Grove, Raspberry Pi, BeagleBoard ve ESP tabanlı ürünler gibi popüler ürünlerle kolay entegrasyon sağlar.
Seeed Studio XIAO ESP32S3 Sense & Seeed Studio XIAO nRF52840 Sense
Seeed Studio XIAO Serisi, benzer bir donanım yapısına sahip, parmak boyutunda küçücük geliştirme kartlarıdır. Buradaki kod adı “XIAO”, yarı özelliği “Tiny” ve diğer yarısı “Puissant” anlamına gelir.


Seeed Studio XIAO ESP32S3 Sense, bir OV2640 kamera sensörü, dijital mikrofon ve SD kart desteği entegre eder. Gömülü ML hesaplama gücü ve fotoğrafçılık yeteneğini birleştirerek, bu geliştirme kartı akıllı ses ve görsel AI ile başlamak için harika bir araç olabilir.
Seeed Studio XIAO nRF52840 Sense, Bluetooth 5.0 kablosuz yeteneğine sahip olup düşük güç tüketimi ile çalışabilir. Yerleşik IMU ve PDM ile, gömülü Makine Öğrenimi projeleri için en iyi aracınız olabilir.
Daha fazla bilgi için buraya tıklayın ve XIAO ailesini keşfedin!
SenseCraft AI
SenseCraft AI kolay AI model eğitimi ve dağıtımı için no-code/low-code bir platformdur. Seeed ürünlerini yerel olarak destekleyerek, eğitilen modellerin Seeed ürünlerine tam uyumunu sağlar. Ayrıca, bu platform aracılığıyla modelleri dağıtmak, web sitesinde tanımlama sonuçlarının anlık görselleştirilmesini sağlar ve model performansının hızlı bir şekilde değerlendirilmesine olanak tanır.
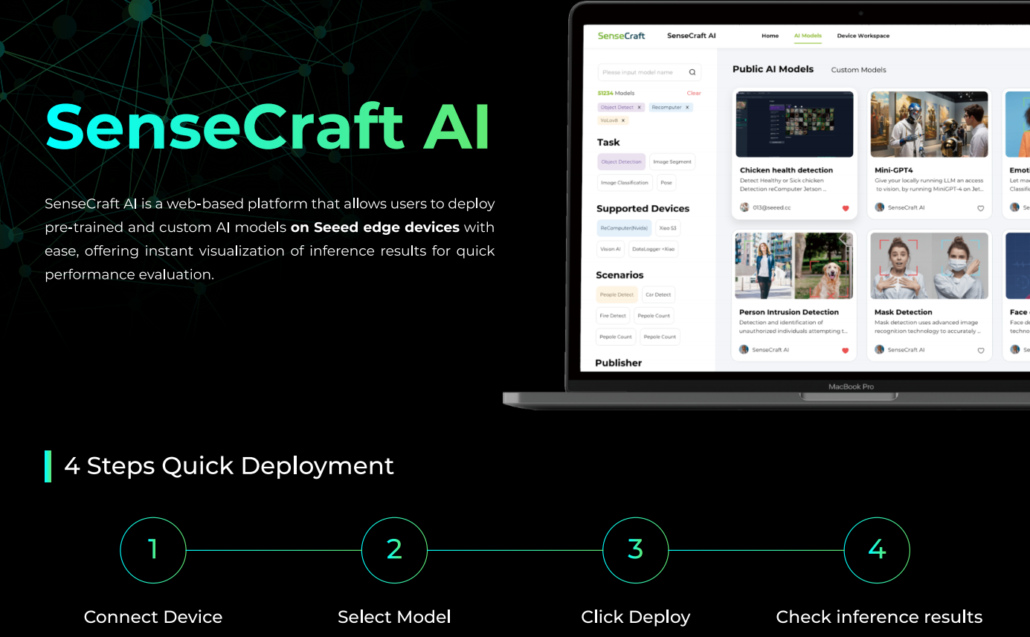
tinyML uygulamaları için ideal olan bu platform, cihazı bağlayarak, bir model seçerek ve tanımlama sonuçlarını görüntüleyerek, hazır veya özel AI modellerini zahmetsizce dağıtmanıza olanak tanır.